Dr. Alper Yegenoglu
Postdoc in Artificial Intelligence and Computational Neuroscience
SDL Neuroscience, Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich, Jülich, Germany
Institute of Geometry and Applied Mathematics, Department of Mathematics, RWTH Aachen, Aachen, Germany
Biography
Alper Yeğenoğlu is a postdoc in artificial intelligence and computational neuroscience. He received his PhD (Dr.rer.nat) in computer science in 2023. His research interests include bio-inspired learning, meta-learning, neuro-architecture search, agent-based modelling and gradient-free optimization with population based techniques (metaheuristics) such as evolutionary algorithms.
Interests
- Artificial Intelligence
- Computational Neuroscience
- Meta-learning, learning to learn
- Neuro-architecture search, AutoML
- Gradient-free Optimization
- Metaheuristics
- Agent based modelling and swarm intelligence
Education
PhD in computer science, 2023
RWTH Aachen
Skills
Technical
Python
Artificial Intelligence
Computational Neuroscience
Hobbies
Music
I do electronic music, especially synthwave. You can listen to my music at https://soundcloud.com/electric-courage and https://electriccourage.bandcamp.com/
Table-tennis
Reading
Experience
Topics include:
- Gradient free optimization methods applied on
- Artificial and spiking neural networks (SNNs)
- Emergent self-organization and self-coordination in multi-agent systems steered by SNNs
- Meta-Learning and Multi-task learning with SNNs on high performance computing systems
Duties involved:
- Implementation of statistical analysis methods for electrophysiological and analog time series data
- Maintaining the Electrophysiology Analysis Toolkit Analysis Toolkit (Elephant)
- Supporting other scientists implementing additional analysis methods
Featured Publications


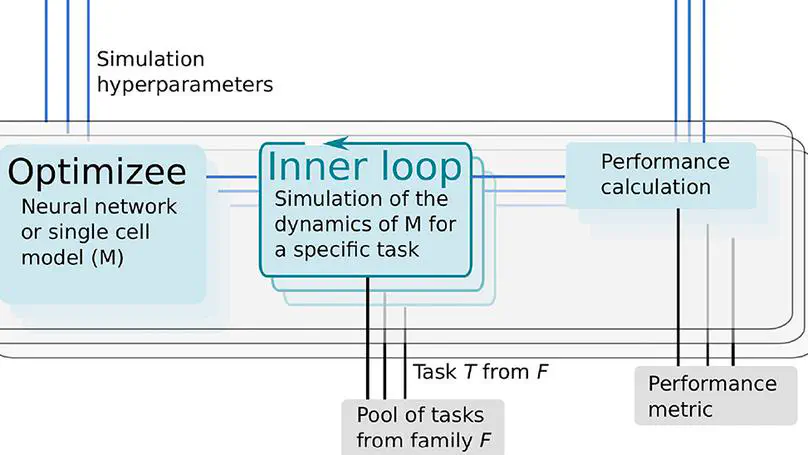
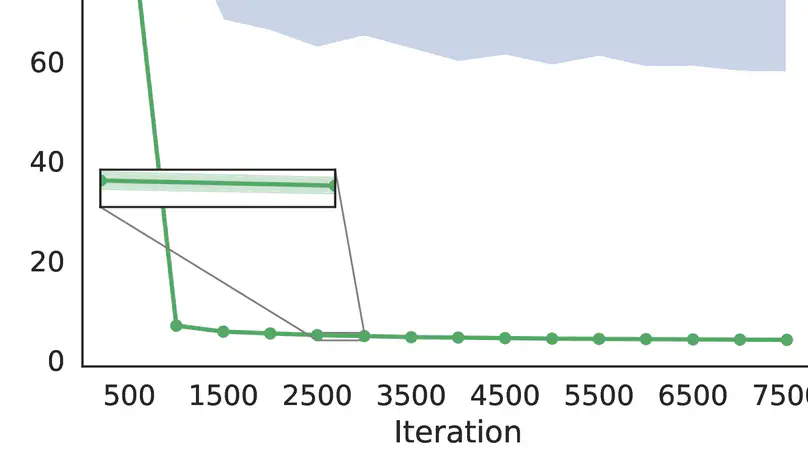
Recent Publications
Quickly discover relevant content by filtering publications.
(2025).
Multi-Agent Systems Powered by Large Language Models: Applications in Swarm Intelligence.
arxiv.
(2024).
Leveraging cognitive dynamics for bio-inspired reservoirs (in preparation).
Peer Community in Registered Reports.
(2024).
Multidisciplinary and collaborative training in neuroscience: Insights from the Human Brain Project Education Programm.
Springer - Neuroinformatics.
(2023).
Two-compartment neuronal spiking model expressing brain-state specific apical-amplification,-isolation and-drive regimes.
arXiv preprint arXiv:2311.06074.
