Ensemble Kalman Filter Optimizing Deep Neural Networks: An Alternative Approach to Non-performing Gradient Descent
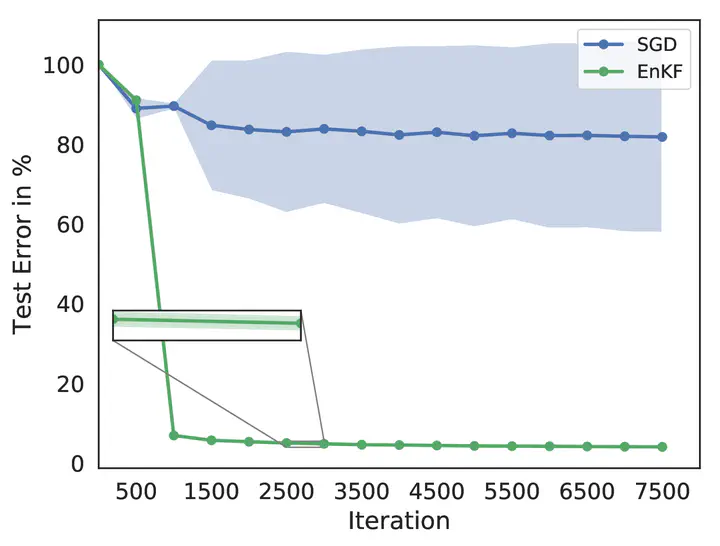 Mean test error of a CNN optimized with SGD and EnKF applied on the MNIST task.
Mean test error of a CNN optimized with SGD and EnKF applied on the MNIST task.Abstract
The successful training of deep neural networks is dependent on initialization schemes and choice of activation functions. Non-optimally chosen parameter settings lead to the known problem of exploding or vanishing gradients. This issue occurs when gradient descent and backpropagation are applied. For this setting the Ensemble Kalman Filter (EnKF) can be used as an alternative optimizer when training neural networks. The EnKF does not require the explicit calculation of gradients or adjoints and we show this resolves the exploding and vanishing gradient problem. We analyze different parameter initializations, propose a dynamic change in ensembles and compare results to established methods.
Type
Publication
International Conference on Machine Learning, Optimization, and Data Science